Edited 11/07/2020 for updated advice and to belatedly address discussions in this reddit post
The C++ language is one of the most widely used programming languages in the world. In 1998, the first standard ISO C++ version was published, known as C++98. No significant updates were made for 13 years, and full compiler support took longer – making C++98 the traditional version of the language for many programmers. The updates made in 2011 for C++11 were so substantial that creator Bjarne Stroustrup stated, “C++11 feels like a new language … the pieces just fit better together”. While this is definitely a good thing, transitioning to what “feels like a new language” may seem burdensome for the busy programmer.
This article strives to serve as a map for navigating the multitude of new features and libraries in the transition from C++98 to C++11. Many references for this version exist, but are either longwinded, non-comprehensive, or cater to a different audience. What’s lacking is a frank assessment of C++11 features for the everyday programmer – advice and general rules for how to easily become a better C++ programmer using the improved C++11 toolset. This article is intended to fill that role, by offering brief definitions, examples, and practical advice for each new feature in roughly sorted order of importance and frequency of use. All opinions are my own, based on experience mixed with thoughts from foremost C++ experts; the reader should give careful consideration and form their own opinions.
Table of Contents
- Critical Changes
- Important Features
- Minor Features
- Templated Library Development Features
- Esoteric and Advanced Features
- References
Introduction
The C++ language is one of the most widely used programming languages in the world1. In 1998, the first standard International Standards Organization (ISO) C++ version was published, known as C++98. No significant updates were made for 13 years, and full compiler support took longer – making C++98 the traditional version of the language for many programmers. The updates made in 2011 for C++11 were so substantial that creator Bjarne Stroustrup stated “C++11 feels like a new language … the pieces just fit better together” 2. While this is definitely a good thing, transitioning to what “feels like a new language” may seem burdensome for the busy programmer. This article strives to serve as a map for navigating the multitude of new features and libraries in the transition from C++98 to C++11.
One might question the need for this writing, as there are many books and articles on the topic already. There are indeed excellent videos3, books4, FAQ pages5, blog posts 6, feature lists 7, and general C++ reference pages89. The everyday C++ programmer is proficient and applies coding to real world problems. They may not have time to read a whole book on the topic, or do the research required to separate the useful features from the obscure. They ideally want to write safe, elegant, performant code, but getting results is top priority; general rules of thumb are therefore more useful than longwinded case explanations. The opinioned references out there are either non-comprehensive 6, too basic 10, or cater to programmers with more advanced library-building use cases 4. What’s lacking is a frank assessment of C++11 features for the everyday programmer – advice and general rules for how to easily become a better C++ programmer using the improved C++11 toolset.
This article is intended to fill that role, by offering brief definitions, examples, and practical advice for each new feature in roughly sorted order of importance. More complete definitions and examples should be sought in other references. The step up from C++98 to C++11 is much greater than C++11 to C++14 or C++17, so in the interest of brevity this article will focus exclusively on C++11. All opinions are my own, based on experience mixed with thoughts from foremost C++ experts such as Bjarne Stroustrup 2, Herb Sutter 6, and Scott Meyers 4. I have extensively used their ideas and examples to present in this format, and so will not always cite inline. The reader should carefully consider all information and form their own opinions.
Critical Changes
There are a few language and library changes that are so impactful, they deserve their own section. If only three things about C++11 could be highlighted, these are the ones.
Move Semantics
Definition
Arguably the single largest categorical change to the C++ standard ever is what’s called move semantics. This is because it fundamentally changes the game for memory management and allows for other constructs that previously would not be possible, e.g., unique_ptr. The basic idea behind move semantics is that we have knowledge that a thing being copied will never be used by the caller again. Instead of wasting time doing a deep copy of all of its data, let’s just recycle its resources for ourselves! This allows the opportunity for incredible performance gains to be harvested: if the move constructor is a constant time operation like in many standard containers (vector, map, unordered_map, string, e.g.), then it can be many orders of magnitude faster than the copy constructor for large containers 11 12. How can we know it’ll never be used again? It must be what’s referred to as an rvalue (pronounced ‘arr-value’), which means it’s a temporary, fleeting value, that can’t possibly be referenced thereafter. In the code below, user is an lvalue (as in left side of the assignment, pronounced ‘ell-value’), and the temporary c-string literal “Skywalker” is an rvalue (as in right side of the assignment). We can continue to use the variable user after this line executes, but there is no way to reference the temporary string. This is a slight oversimplification, but for discussion purposes it’s accurate enough!
string user("Skywalker");
The figures below show a silly but accurate real-life example – the blue person buys all new furniture for their house to match the red neighbor in a copy constructor representation (Figure 1), but in a move constructor (Figure 2) they inherit all furniture from the red person who no longer has a use for them. Just as the blue person will save a lot of money on furniture, so too can code save on execution time!
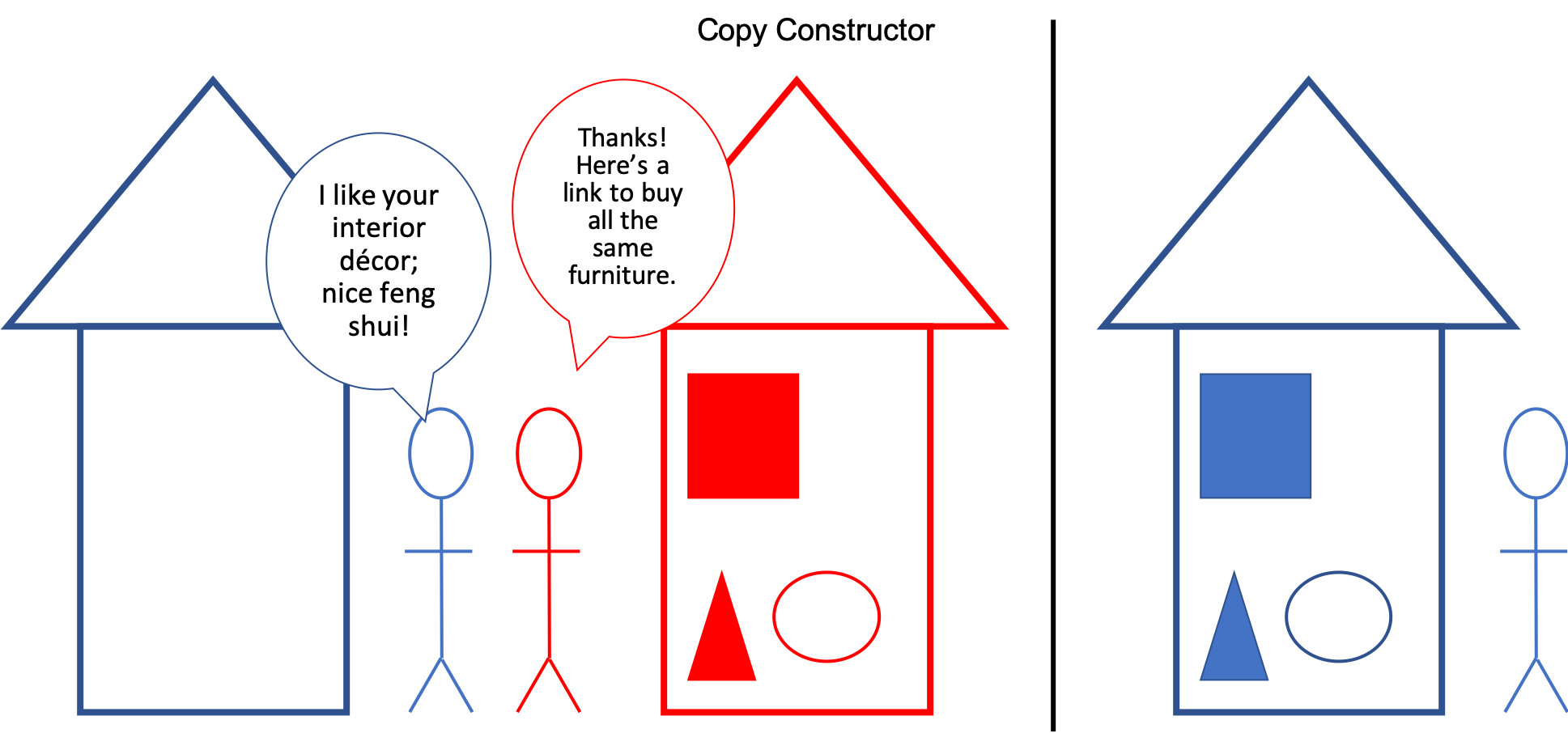 Figure 1. Copy constructor representation with furniture – all new purchases
Figure 1. Copy constructor representation with furniture – all new purchases
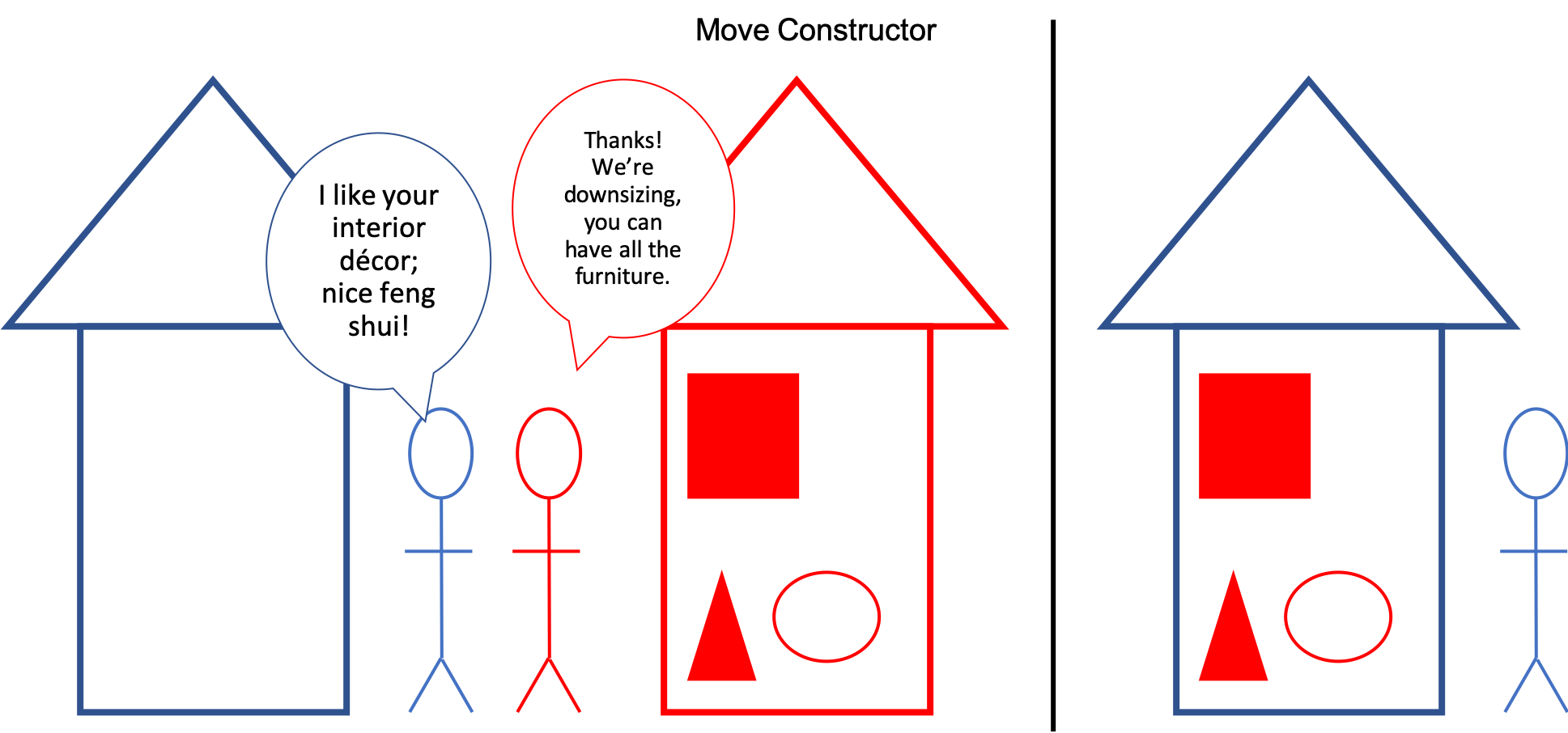 Figure 2. Move constructor representation with furniture – transferred by neighbor
Figure 2. Move constructor representation with furniture – transferred by neighbor
Below is both a copy constructor and a move constructor in code – the latter is what is called when the argument is an rvalue, as in the code line above. Notice the differences between a typical copy constructor and the move constructor: the move constructor’s argument is not const and has two “&” characters (called an rvalue reference), and instead of making a copy it steals the storage pointer from rhs. This is safe to do because it’s guaranteed that rhs is not needed anymore. Move semantics are also often applied to the assignment operator in a similar way.
// Copy constructor
string(const string& rhs) {
allocateSpace(myDataPtr);
deepcopy(rhs.myDataPtr, myDataPtr);
}
// Move constructor
string(string&& rhs) {
myDataPtr = rhs.myDataPtr;
rhs.myDataPtr = nullptr;
}
If you have a referenceable variable (lvalue) but want to pass its value elsewhere, you can declare that you’re done with the variable, thus allowing the move constructor to be used. To do this, simply pass the variable into a constructor, surrounded by a call to std::move(). “Move” – poor naming notwithstanding – essentially means you can treat the parameter as an rvalue from now on. In a later section 2.2, unique_ptr will be discussed which is an object that cannot be copied at all, it must_ be moved. That’s because it wants to enforce intentional ownership transferal from one object to another. This means we have to be careful not to use the variable after it has been moved from, without reinitializing it first. Examples below will use a general MoveOnlyObject to illustrate this point, as unique_ptr is only one such class.
MoveOnlyObject a;
...
MoveOnlyObject b(a); // ERROR – copy constructor doesn't exist
MoveOnlyObject c(std::move(a)); // OK – ownership transferred to c. a is DEAD now
cout << *a; // RUNTIME ERROR – illegal access
The code above uses a after it’s been move()‘d from, which is undefined behavior. One way to protect from this is to make sure the variable is out of scope after it’s move()‘d, like below.
MoveOnlyObject c;
{
MoveOnlyObject a;
...
c = MoveOnlyObject(std::move(a));
} // can't even attempt to dereference a anymore
Another use case to keep in mind is inserting objects into a container. If the local object won’t be used anymore, it can be move()‘d instead of copied, saving the unnecessary copy.
vector<string> importantUsers;
...
string localUser;
... // compute local user
allUsers.push_back(std::move(localUser));
A few additional notes about move semantics need to be said. Firstly, the double ampersand (&&) notation can be used in other related contexts, in what’s called a universal reference, but the uses for this (perfect forwarding, universal template), are advanced and so are not discussed here. Secondly, memory on the stack can’t be re-used, which means classes with only automatic-scope variables will not benefit from a move constructor if they are instantiated on the stack. One can still create a move constructor for such a class, but it’s better to let the compiler automatically create it in this case (see Control of Defaults for more detail). However, code with a vector containing that class, for example, will still benefit from the existence of move semantics because the vector’s storage can be re-used. For this reason, some people say that turning on support for C++11 gives automatic performance benefits for “free” (assuming use of standard containers).
Advice
- Understand move semantics and how they affect the performance of code.
- If passing ownership of a container to another container or function, use
std::move(). - It’s recommended to declare the moved variable in a scope block that ends right after the variable is moved, so there is no possibility of re-using the moved variable.
- Follow the rules of zero and five 13 (see Control of Defaults for more detail) and make sure that any class with a defined copy constructor also defines a move constructor.
Smart Pointers
Definition
Any C++ programmer would probably agree that one of the most difficult aspects of the language is manual memory management. Every new must be matched with exactly one delete, and the same for malloc/free and new[]/delete[] (and don’t mismatch!). Covering every possible case and return path (including exceptions) can prove daunting for even language experts, with often dire consequences of memory leaks or segmentation faults. C++11 provides an incredible tool set to nearly eliminate this problem, while retaining the power and flexibility that make C++ such a great language.
The tool set is called Smart Pointers, of which there are three types: unique_ptr, shared_ptr, and weak_ptr. Previously there existed a type called auto_ptr which attempted to do the job of unique_ptr but could not due to the lack of move semantics; auto_ptr is thus now deprecated and should not be used. Regular, native pointers are often now called raw pointers (as opposed to smart pointers).
A unique pointer represents singular ownership over the held object, hence the word unique. It does not have a copy constructor, only a move constructor. Referring to the above section on move semantics (2.1), this means that ownership cannot be duplicated, only transferred! This is paramount to ensuring each new corresponds to exactly one delete. And since the pointer is wrapped in a class type, delete is called automatically whenever the unique_ptr is destructed, meaning that the memory is safely handled without the programmer needing to worry about it. Read: no more memory leaks or double deletions! The overhead of using this type over a simple built-in pointer is miniscule, thus giving us no real downsides to its usage. Do not call delete manually, as that will certainly cause a double deletion error.
Unique pointers should be created by make_unique() (not provided until C++14 but can be imported easily into the code base 14). This function is safer than creating a pointer with new and then passing that into a unique_ptr. Or at least the pointer should be passed directly into the wrapper without any other throw-able functions or statements in between (or even in the same line). The below code shows multiple areas of concern when manually managing dynamic memory, and indeed several mistakes are made.
char buffer = new char[bufferSize];
try {
doStuff(buffer); // consumes and deletes the buffer
} catch (...) {
// Was buffer deleted before exception thrown??
delete buffer; // Oops, forgot delete[] – memory leak!
...
return;
}
delete[] buffer; // Oops, double delete if exception was thrown!
Using unique_ptr instead, the code can be neater and we don’t have to worry about cleaning up the dynamic memory.
{ // Block not needed but good practice to prevent use of buffer after move
unique_ptr<char[]> buffer = make_unique<char[]>(bufferSize);
try {
doStuff(std::move(buffer)); // transfer ownership
} catch (...) {
... // No explicit delete needed here or below
}
}
Another effective usage of the type, shown above, is to enforce ownership transferal at compile time. In the code below, a C++98 function consuming a buffer can’t enforce ownership except by socialization and function comments. If the caller accidentally uses the buffer afterwards, they will run into trouble. In the unique_ptr version, however, the caller must consciously transfer ownership to consumeBuffer() using std::move(). Unfortunately, the caller cannot be prevented from trying to use buf afterwards, but the presence of the move() call provides a visual cue that it shouldn’t be done.
// WARNING buf is invalid afterwards!
void consumeBuffer(char[] buf);
// buf is known to be invalid afterwards since ownership is transferred
void consumeBuffer(std::unique_ptr<char[]> buf);
Shared pointers (shared_ptr) allow one object to be shared by multiple users by making sure that while a reference to the pointer is still being held, the object will not be deleted. This is achieved by keeping a separately-allocated structure containing the shared reference count for each object. When a copy is made, the reference count is increased, and when that copy is destroyed the count is decreased; the shared object is finally deleted when the reference count hits 0. While being a useful utility, it should not be the default choice due to the significant overhead involved. If the application will benefit from shared pointers, it will likely be fairly clear, and the overhead worth the extra safety / ease-of-use / cleanliness. One example is for large objects in a cache: eviction from the cache doesn’t cause the object to be deleted until the last user is done with it – this avoids improper access to a destroyed object while ensuring memory is cleaned up. This concept is loosely illustrated in the code below. Akin to their unique counterparts, shared pointers should be created with make_shared() which again is safer, but also cuts dynamic memory allocation in half (see emplacement for the reason why).
// Simple LRU Cache put() fragment using make_shared()
template <typename KEY, typename VAL>
LRUCache::put(const KEY& key, const VAL& value) {
...
if (!contains(key)) {
storage[key] = std::make_shared(value);
}
...
}
...
// Even if element is evicted from cache, the object is not destroyed, as it's shared
std::shared_ptr<LargeObject> localSharedUser = lruCache.get(someKey);
Weak pointers (weak_ptr) are akin to shared pointers but do not contribute to the shared reference count, so the object can be deleted even if a weak pointer is still held. In order to access the pointed-to object, you must check for validity and convert to a shared_ptr atomically using lock(). This type is the least common, but can be beneficial in certain cases like in breaking circular reference chains. Additional reference used throughout this section: 15.
Figure 3 shows another comic illustration, this time comparing pointer types. Of course, it’s not a perfect representation but it elucidates the point: the left skydiver (unique pointer) has a high degree of safety with a single parachute on. The middle diver (shared pointer) paid a higher cost for two parachutes but won’t be let go while either one is attached. The right diver (raw pointer) is hoping they can fall exactly into the narrow zone of the trampoline – not safe! Weak pointer is not illustrated.
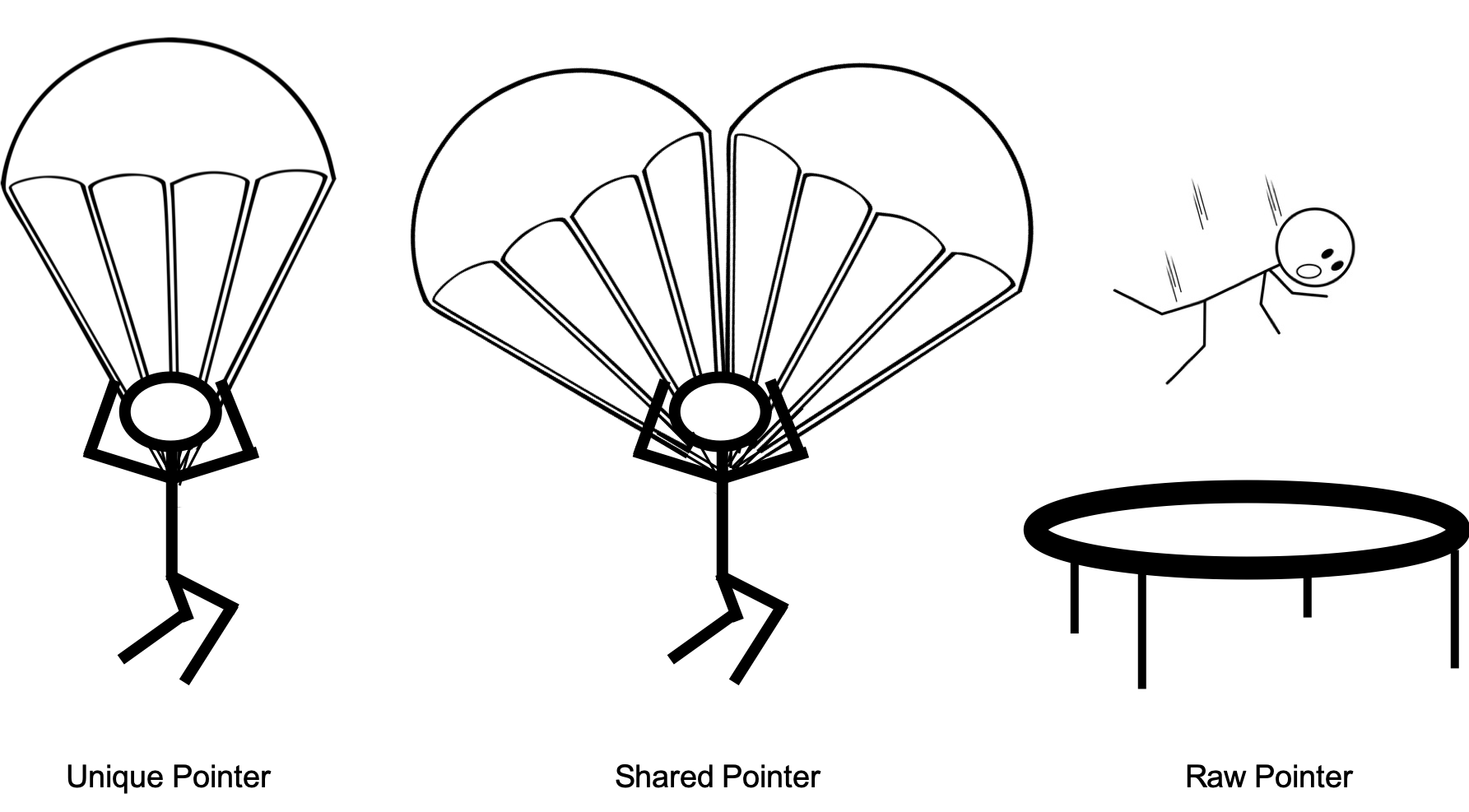 Figure 3. Comic illustration of unique vs shared vs raw pointers
Figure 3. Comic illustration of unique vs shared vs raw pointers
Advice
- Always use smart pointers over raw pointers to convey ownership.
- Use
unique_ptrfor single ownership,shared_ptrfor shared ownership, andweak_ptrto break cycles in shared pointers. - Always use
make_unique()/make_shared()or construct the smart pointer around the created pointer with no other expressions happening between or concurrently. - Never use
auto_ptr, as it is now deprecated in favor ofunique_ptr. - Don’t make a
shared_ptrout ofthis, without researching and usingshared_from_this; definitely don’t make aunique_ptrout ofthis.
Hash Maps and Sets
Definition
Unordered associative containers, colloquially known as hash tables, are extremely useful containers supporting O(1) insert, lookup, and delete. The properties of an object are combined and distilled down to one integer key as part of the hashing process. Two variants are typically discussed: map (key is associated to and stored with a value) and set (just the key). In C++98, these constructs are seemingly provided by map and set, however, the astute C++ programmer will know that those containers offer a less optimal O(lg N) insert, lookup, and delete. Typical library implementations employ a self-balancing binary tree like the Adelson-Vesky-Landis (AVL) or red-black tree. The advantage of this is that it’s ordered; namely, iterating over the container beginning to end will yield a sorted list. Additionally, only the < operator needs to be defined for the key type, instead of a typically more complex hash function. But good hash functions are easy to come by, and more often than not the order invariant is not needed, so the hash map is often the best option.
Hash tables could be ported in through other means like the Standard Template Library (STL) hash_map or boost::unordered_map. Fortunately, standard C++11 code can now make use of unordered_map and unordered_set (unordered_multimap and unordered_multiset too, technically). The unordered part is to contrast with the ordered-ness of regular maps, as well as for the unlucky fact that the better name hash_map was taken by the STL. The API for using unordered_map is almost identical to that of map, so programmers familiar with the latter should have no difficulty making the switch. The only consideration is for class writers needing to make their class hash-able (by specializing the templated function object hash) – a good hash function is paramount to the effective use of a hash table. Many common types including all primitives and std::string already have a hash function provided, and methods for combining multiple properties into one single hash are available 16. Below is an example declaration of this type.
std::unordered_map<std::string, int> userToIndexMap;
Advice
- Always use
std::unordered_mapandstd::unordered_setin place of other unordered associative containers, unless they provide additional needed functionality or significant measured performance gains. - When in need of a lookup container, default to using
unordered_mapandunordered_setovermapandset, unless the strict ordering is needed. - Do be aware that due to spatial locality of memory and overhead of the hashing, a hash table can be slower than a binary tree or even a simple linear search in some circumstances, especially with small container sizes 17.
Important Features
Features in this section are important for the everyday programmer to know about. Some make catching bugs early easier, some provide more expressive power, and some simply make code more elegant and readable. All are good to know, even for simply being able to recognize their usage in others’ code.
Code Safety / Bug Catchers
Some of the most important language features exist to help catch logic bugs at compile time instead of runtime, where it’s notoriously more expensive to find and fix. Strongly-typed variables, function signature matching, and compiler warnings all help with this. C++11 adds a few more tools to add to the bug-catcher’s belt.
Named null pointer
Definition
C and C++98 (even Java and other) language programmers should be very familiar with the null pointer, especially if you’ve gotten bit by an unchecked null pointer leading to a segmentation fault! Some may not know, however, that the keyword NULL is actually not a keyword at all but a preprocessor definition, and some compilers simply define it as the integer 0. Which works out fine until it doesn’t. In the code below, it looks as though all users should be printed because the const User* printMe() overload says that’s what it will do. In this case though, NULL gets interpreted as long int 0 and thus better matches the printMe() taking an integer parameter. The user with index 0 gets printed, instead of all users! This may seem contrived, but there are many other examples of legitimate mistakes that could be made due to this confusion. Pointers should not be compared or set to NULL or 0, but instead to the new keyword nullptr which is always of pointer type and never integer.
void printMe(long int userIndex); // prints user given index
void printMe(const User* user); // prints user, or all if NULL
printMe(NULL); // prints all users? NO
Do this!
if (myPtr == nullptr || myOtherPtr == nullptr || myThirdPtr == nullptr) { // YES!!
return nullptr; // YES!!
}
Not this!
if (myPtr == NULL || !myOtherPtr || myThirdPtr == 0) { // NO!!
return NULL; // NO!!
}
Advice
- Never compare or set pointers directly with/to integer 0 or
NULL. - Always use the new language keyword
nullptr.
Inherited Function Override Controls
Definition
If a derived class is to override the implementation of a base class’ function, the base class function must be declared with the keyword virtual, and the two function signatures must match exactly. This has led to many confusing bugs in practice.
class User {
virtual void print();
virtual string getName() const;
void performAction(const Action& a); // note: not virtual!
};
class PowerUser : User {
void print(); // overrides User::print
string getName(); // doesn't override User::getName - missing const
void performAction(const Action& a); // doesn't override - base func not virtual
};
In C++11, a function can now be marked with override, meaning that it should override a base class function (this should be familiar to Java programmers). If it does not actually do that, the compiler will throw an error, helpfully catching the bug much earlier than the programmer might. The PowerUser class can be written better using this keyword, as below.
class PowerUser : User {
void print() override; // OK: overrides User::print
string getName() override; // ERROR: wrong type
void performAction(const Action& a) override; // ERROR: base func not virtual
};
An additional modifier final can be used, which says that the function or class cannot be overridden (or extended in the case of a class). There aren’t typically good use cases for wanting this to be the case 2, so this modifier can usually be avoided. However, it can provide a small performance benefit by allowing the compiler to remove some virtual function calls 18 (though Stroustroup argues this will be negligible).
Advice
- Always use the
overridekeyword when a derived class function is supposed to override a base class function. - The keyword
finalshould probably not be needed, but it can potentially provide a small performance benefit by de-virtualizing function calls.
Control of defaults
Definition
Certain functions in a class are automatically generated by the compiler for ease of use. These are the default constructor, copy constructor, copy assignment operator, destructor, and since C++11, move constructor and move assignment operator. For example, the compiler-generated copy constructor will simply go through all of the class’s members and perform their respective copy constructors in turn. Unless the class is managing its properties in a special way, the compiler-generated constructors/destructor are almost always the right choice. However, if you specify a copy constructor specifically, the move constructor will not be generated by the compiler, and thus quietly not benefit from performance improvement opportunities provided by move semantics. It’s also easy to miss a property in the copy or default constructors. Many other rules abound, making it difficult for the everyday programmer to get right.
This is why the so-called “Rule of Five” was created – if any of the “Big Five” compiler-generated functions are defined, all of them should be. I think it’s more accurate to include all six compiler-generated functions (typically the default constructor isn’t included in this count for some reason). And even more succinctly, the most common cases can be covered by the “Rule of Zero” which says that unless the class is performing special memory management, the compiler defaults suffice 13. C++11 allows the writer to be precise about these functions and set them to default if the compiler-generated version is wanted, or to delete if that function should not be made available at all. The rules are combined using these C++11 concepts for the “Rule of Six or Nothing”: if a class must declare any of the destructor, copy/move constructor, or copy/move assignment operator, all others in this set should be default or delete – all other classes (the majority) should declare none of them or set all to default 19 20. These keywords are shown being used in the example below.
class User {
User(const User&) = default; // accept default copy construction
User& operator= (const User&) = delete; // disallow copy assignment
User(User&&) = default; // accept default move constructor
User& operator= (User&&) = default; // accept default move assignment
~User() = default; // accept default destructor
};
As a last note, this rule also applies to a base class having a virtual destructor. If the base class is to be used for polymorphism (rule of thumb: if and only if it has a virtual function), it should have a virtual destructor so that the derived object can be properly deleted from a base class pointer. In this case, the copy constructor should likely not be allowed so as to prevent object slicing situations where derived objects are copied into a base object, causing them to lose all derived object functionality.
Advice
Follow the “Rule of Six or Nothing”:
- If a user-defined class needs only the compiler-generated functions (the most common case), do not declare any, or declare all as
default. - If any of these functions are defined (including a virtual destructor to support polymorphism), however, all six must be either defined or set to
default/delete. - Always specify a base class or compiler-generated function as
deleteif it is to be disallowed, as opposed to the C++98 way of declaring it private and not defined.
Standard Array
Definition
You could always create C-style arrays on the local memory stack with a fixed size. New in C++11 there is a standard container array that acts like a native array (including allocation on the stack) with little to no overhead, but also has some additional benefits. It can be used with all C++ standard container algorithms like find() and count(), and it will not decay to a pointer which makes it better for type-safety. To illustrate the latter point, the below code creates a C-style array of User objects. The printMe() function doesn’t define a specific array parameter version, so the compiler will naively decide to “decay” allUsers into a User pointer. Now, only one User is printed instead of all 50 like the caller might have expected.
printMe(User * user) { … } // prints user pointer
User allUsers[50]; // native C-style array
printMe(allUsers); // OOPS, only the first user is printed
Using array, this bug is caught at compile time.
array<User, 50> allUsers;
printMe(allUsers); // ERROR - no matching function
Advice
- Strongly consider using
std::arrayinstead of a built-in array of fixed size. - The only exception should be in the scenario that performance testing shows an unacceptable speed loss
- usually minimal to none with normal compiler optimizations on.
Brace Initialization
Definition
Initialization of variables in C++98 could be done using the assignment operator =, with a constructor using (), or with curly braces {}, but rules about which method can be used in which scenario are not simple. C++11 extends the brace initialization paradigm to be allowed in just about every case, and thus is referred to as uniform initialization in the standard. An argument for always using brace initialization is that it ensures variables are initialized and avoids the so-called “Most Vexing Parse” 4 problem that calling an empty constructor can have. Uninitialized variables can be caught by compiler warnings, and I have not known the Most Vexing Parse to trip up C++ programmers often. Therefore, I don’t see the argument compelling enough to warrant a paradigm shift in basic variable initialization. Here are the three ways of initialization.
string username = {"Vader"};
string username{"Vader"};
string username = string{"Vader"};
To help achieve this uniformity, most standard containers now accept std::initializer_list as a constructor argument. This type is a homogeneous arbitrary-length list which is created by the use of braces. This can be useful for initializing containers in-line with specific values which could not be done before. The brace notation can be nested in order to initialize a vector or map, for example.
vector<int> actionIndexes = {1, 2, 3, 4};
map<string, int> nameToIndexMap = { {"Vader", 1}, {"Skywalker", 1} };
One caveat to be aware of is that initializer list constructors will often be preferred over other constructors. In the code below, the first line uses the constructor which takes a size for the vector, in this case 5. The subtle difference in the second line is the use of curly braces for brace initialization, which results in the initializer list constructor being used, putting a single value of 5 in the vector. Clearly these are two very different results.
vector<int> v(5); // vector of size 5
vector<int> v{5}; // vector with 1 value which is 5
Finally, class member variables can be given an initial value in the class declaration using brace initialization where the member is defined, called member initialization. If there are multiple constructors and member variables, initializing the members after their declaration can be clearer and more bug-resistant than setting each variable in the constructor. It’s easy to overlook setting a particular variable in the constructor, but it’s obvious if a variable is not followed by a brace initialization. If the variable is also set in the constructor, that assignment will take precedence.
class User {
User() {} // don't need to initialize default here, already done
String username {"John Doe"};
};
Advice
- Use brace initialization for initializing containers and classes supporting initializer list construction to hold particular values.
- To avoid confusion as in the caveat mentioned above, it’s recommended that brace initialization be used in conjunction with the assignment
operator =instead of on its own like a constructor. - For regular variable initialization, use the constructor or assignment operator.
- Initialize all class member variables using in-class brace initialization.
More Power
It would not be a good thing to graft every useful utility or nifty feature in another language or library into standard C++. New language constructs or libraries are added if they will be beneficial to a large percentage of the user population by adding expressive power or higher efficiency. But let’s face it: in the real world of C++ software development, features in the standard library are easier to use and more palatable than importing an external toolset, so it’s great when features are offered in the standard.
Constexpr
Definition
A primary trend of modern C++ is attempting to do as much code evaluation at compile time as possible. Doing so means less work is done at runtime and thus faster programs. C++11 took the first step on this path by introducing constexpr (often pronounced const-ex-per), which is short for constant expression. If an expression cannot be computed at compile time, i.e., it’s dependent on some runtime variable, constexpr can’t be applied to the variable. For this reason, there are a variety of restrictions imposed on when this construct is allowed, but each revision of the standard removes some of these constraints. Variables can be declared constexpr which will make them be inlined in code by the compiler like a macro, but the real novelty comes with declaring functions constexpr. The canonical example is the ability to compute the factorial of a number at compile time, as shown below. Note that factorial() can be called with a runtime variable without a compile error, unlike the case with variables mentioned above, but then the recursion will happen at runtime – so don’t expect to be able to toss constexpr onto the front of any function and no longer need to worry about runtime performance. Outside of this sandbox example, it is often useful for applications like unit conversion constants, compile-time constant parsing, or global objects of small classes.
constexpr long long factorial(int n) {
return n <= 1 ? 1 : (n * factorial (n – 1));
}
factorial(4); // 24 - computed at compile time!
factorial(someNumber); // slower, computed at run time!
Advice
- Prefer
constexproverconstfor static, unchanging class variables. For integer types the two mean the same but for any other type constexpr is more correct. - Prefer
static constexprmember variables over#definemacros, because they retain type safety and will likely be inlined anyways. - Take
constexprinto consideration for runtime performance optimization opportunities when a result can be pre-computed.
Lambdas
Definition
In many circumstances, it can be useful to define custom functions or function objects to pass into other functions, as in the standard algorithms module’s for_each() and count_if(). For simple operations, this can get quite tedious, leading to the (probably correct) conception that standard algorithms are cumbersome to use. C++11 provides a language construct called lambda expressions to make it easier to create these one-off functions in place. The basic format is:
[capture list] (parameter list) { function body }
The type of the object created by a lambda expression is a std::function. Below you can see code using a traditional function passed as a function pointer to count_if(), and then the same functionality using the new lambda expression. The advantages in this case are that this extremely specific function is not exposed to the rest of the code, and that the case definition is in-line. The advantages do not quite outweigh the cost in this case.
// Using named function
bool isLannister(const string& username) {
return username.find("Lannister") != string::npos;
}
int numLannisters = std::count_if(usernames.begin(), usernames.end(), isLannister);
// Using lambda
int numLannisters = std::count_if(usernames.begin(), usernames.end(),
[] (const string& username) {
return username.find("Lannister") != string::npos;
});
If a variable is needed for the function, the only solution is a function object, also called a functor. This is just a class where the operator () is overloaded. Lambda expressions can be used instead to create an anonymous functor class called a closure. To do this, you simply “capture” variables that are to be used, by naming each variable in a comma-separated list inside the capture brackets, preceded by = for by-value or & for by-reference. In this case, the functor version is quite verbose and has awkward syntax, whereas the lambda version is clearer and more concise. All local variables can be captured, but the convenience is not worth the higher risk of dangling references and decreased readability, so this should not be done. Member variables can’t be captured, but instead you can capture the this pointer.
struct Contains {
const string& substr;
Contains(const string& substr) : substr(substr) {}
bool operator () (const string& username) {
return username.find(substr) != string::npos; }
};
string stark = "Stark";
int numStarks = std::count_if(usernames.begin(), usernames.end(), Contains(stark));
int numStarks = std::count_if(usernames.begin(), usernames.end(),
[&stark] (const string& username) {
return username.find(stark) != string::npos;
});
In either case, if the function is to be commonly used or is longer than 1 or 2 lines, using a lambda is no longer recommended. Additional reference used for this section: 21.
Advice
- In most common cases, using a lambda expression results in more readability issues for the average programmer than not.
-
There are rare cases where its use can help, though. Use lambda expressions conservatively if the following is true about the function:
- It needs local variables. This is where lambdas can be easier to understand than other code using functors or
std::bind(). - It is short (1 or 2 lines) and non-complex.
- It is not needed in multiple places.
- It needs local variables. This is where lambdas can be easier to understand than other code using functors or
- If a lambda expression is used
- Never use capture-all modes; rather, capture specific variables.
- It’s recommended to not define lambdas on the same line, for readability’s sake; put the lambda declaration on an indented new-line, and the lambda body on another further-indented line, as demonstrated in this section.
Emplacement
Definition
In some standard containers like vector, inserting a new element with push_back() can require more than one call to the constructor, as in the code below. The literal string must first be used to construct a local string, and then the vector can copy-construct that string into the new spot at the end of the vector. Due to the addition of move semantics, a better option is available which avoids extra work: emplace_back(). This alternative essentially tries to construct the object directly in the right place at the end of the vector, instead of first making a temporary object, then copying that over, then finally destructing the temporary object. Note that this is useful in the case that insert is being called with parameters to one of the contained type’s constructors but not an instance of the contained type itself, as in the example below.
vector<string> users;
// first makes string out of "Draco", then copy constructs into vector. Slower
users.push_back("Draco");
// direct construction in place. Faster
users.emplace_back("Draco");
// not faster since constructor explicitly called.
users.emplace_back(string("Draco"));
Advice
Use emplace alternatives to push and insert for more performant code if the following heuristics are true:
- The argument types being passed differ from the type held by the container.
- The insertion is unlikely to be rejected as a duplicate – either the container accepts duplicates or most insertions are unique.
- The insertion will need new object construction – typically, any insertion except placing objects in the middle (not back) of a
vector,deque, orstring.
Concurrency
Another extensive suite of libraries introduced in C++11 revolve around first-class support of something C++98 sorely lacked: concurrency. Concurrent operations are an important method of achieving better performance of programs, but C++ authors were forced to use outside libraries like boost or non-portable base-level solutions like POSIX threads. The new concurrency libraries cover most of what one might hope to achieve with concurrency, with an API consistent with the standard library.
Thread
Threads of execution are the basic building block of concurrent programming, and so are offered in the standard with a simple API. Constructing a thread kicks it off to execute concurrently. Then the parent just calls join() on all threads to wait until they are done, or detach() to allow the parent thread to continue. Threads can be scheduled to sleep for or until a specific time using the chrono library. Access to the primitive thread is allowed for features not provided by the standard API, such as thread priority. Note that as soon as the thread is created, it begins running – there is no function like start. A basic usage example is below.
// spawn new thread that calls computeStuff()
std::thread workThread (computeStuff);
workThread.join(); // pauses until workThread completes
Finally, a new storage class specifier is added to support variables in threads: thread_local. A variable declared static in a function means there will only be one copy of that variable for all callers. Similarly, a variable declared thread_local in a function means there will only be one copy of that variable per thread. The variable will retain its value across multiple calls to the function within the same thread, but another thread will have its own copy.
Atomic Variables
With concurrency comes the problem of ensuring data shared between threads is valid whenever a read occurs – called thread safety. The simplest method is using the atomic library. The atomic part refers to being the most basic building block of operations that cannot be subdivided. This means that calls to these variables are guaranteed to complete before any other thread can make a call to it, thus ensuring thread safety. All built-in integral and pointer types are supported, as well as boolean in the form of atomic_flag. Other types can be used as a template for atomic but must be trivially copyable. Below is an example which allows User objects to be safely created in separate threads when there is a global unique user ID. The post-increment operator ++ is guaranteed to fully complete before any other thread can see the result.
std::atomic<int> latestUserId;
int User::getGlobalUserId() {
return latestUserId++;
}
Mutex
For protecting against concurrent execution of longer sections of code, one would use mutex to guarantee mutual exclusion. The thread simply locks the mutex, performs the critical operation, then unlocks the mutex, ensuring no other threads can enter that code simultaneously. mutex‘es are infamously difficult to ensure provable correctness and can cause data corruption or the program to be hung in deadlock if done wrong. One alleviation available is to use unique_lock which guarantees unlocking at destruction, akin to unique_ptr. Take special caution when using mutexes, and limit the locked time to as short as possible. Compare using a mutex such as below to an atomic variable – it’s easier to use atomic if possible but for complex operations a mutex might be required.
int latestUserId;
std::mutex latestUserIdMutex;
int User::getGlobalUserId() {
std::unique_lock<std::mutex> mutexLock(latestUserIdMutex);
return latestUserId++;
} // mutex is released automatically here
Condition variables
Condition variables (condition_variable), colloquially called condvars, can block a thread from continuing until notified by another thread. Since by definition the condvar is shared between threads, it must be guarded with a mutex or another concurrent-access protection. If the application requires a one-shot notification, Meyers recommends using a void future instead 4.
Async
The root motivation behind concurrency is to parallelize computation for evaluation on multiple cores. As such, the thread is an implementation detail that may be overkill. A simpler alternative is to use async(), which schedules a function to be called at some point in the future and return the result. This task-based orientation to concurrent programming is usually superior to threads because it is conceptually simpler, and likely more performant since we don’t have to solve issues like oversubscription, thread exhaustion, and load balancing. A subtle point on async() brought up by Meyers is that the default scheduling policy does not guarantee the function is called at all, since the scheduler can choose to defer the call until an attempt to access the result is made 4. If true asynchronicity is required, the scheduling policy should be set to launch::async.
Future / Promise
The return of a call to async() yields a future. This object can retrieve a value provided to it, possibly deferred or asynchronously. The caller of async() can then block while waiting for the return value, or periodically check on it while performing other tasks. Two unrelated threads can also remain synchronized in this manner with an additional object called a promise. One thread creates a promise to supply a return value at some point, then sends a corresponding future to another thread which can wait for that return value. This code sample utilizes async() to get the next global user id through an asynchronous call to the function.
std::future<int> idFuture = std::async(getGlobalUserId);
int userid = idFuture.get(); // waits for getGlobalUserId to return
Concurrency Advice
Concurrency in programming is a powerful tool, but can be difficult to get right in a mostly do-it-yourself language like C++.
- Reach for
async()andfutureas the default concurrency tool before turning tothread. - To make shared data thread-safe,
atomicvariables can be used in very simple cases, butmutexis more likely to be applicable. - For control of execution timing and data synchronization,
futureandpromiseare the best option, butcondition_variablealso has its uses.
Regular Expressions
Definition
Regular expressions (regex) are powerful pattern-matching utilities for strings which are ubiquitous in the programming world from programming languages to command line utilities like egrep. C++11 brings the regex module to the standard library, which provides typical match, search, and replace functionality. The regex below replaces “does not” with “does”.
string str("one does not simply use a regex");
regex expr("does not");
str = std::regex_replace(str, expr, "does");
// "one does simply use a regex"
Advice
- Take advantage of the standard regex library if such functions are needed.
- Complex regexes can be simplified a bit with raw string literals.
Time Utilities
Definition
Time points and durations are standardized in the chrono library, providing the programmer with various expressions of time and unit conversions of such. This can be particularly useful for benchmarking code, or for requiring a thread to wait for a duration of time. It’s also more user-friendly than the C library time utilities. For physics-heavy applications, however, chrono may not be suitable yet until C++20 when support for time zones, different clocks like Universal Coordinated Time (UTC) and International Atomic Time (TAI), and calendars are instated.
Advice
- Always use chrono for timing and other duration-based code instead of C time utilities.
- For physics-heavy applications or those needing calendar utilities, a homegrown or external time library may be more appropriate, at least until C++20.
Random Distribution Generators
Definition
Pseudorandom numbers are needed in a wide variety of cases, most notably being games, testing, and simulations. Typically, to generate a random integer between 0 and 100, one might write the below code using C random-number constructs.
int randInt = rand() % 101; // C-style
Experts have noted that even though this appears to be a uniform distribution of random numbers between 0 and 100, the distribution will actually be somewhat skewed 22. It should not be used for any code needing a legitimate random distribution, such as Monte Carlo simulations. A new random library supports real uniform distributions, as well as many others like normal, Poisson, Bernoulli, and chi-squared. Unfortunately, the syntax is a bit clunky, so if the distribution is not of grave concern, it’s simpler to stick with the old way.
std::default_random_engine generator;
std::uniform_int_distribution distribution(0, 100);
int randInt = distribution(generator);
Or to simplify for repeated calls to the distribution, we can create a functor to do this using std::bind() and auto:
auto randomGenerator = std::bind(distribution, generator);
int randInt = randomGenerator();
Multiple problems have been identified in the default random number generator, so it should be replaced by an alternative like Permuted Congruential Generator (PCG), which is a small and fast header-only library 23.
Advice
- For simple programs where the quality of the random distribution is not important to the operation, simple C random number generation will suffice.
- For any practical code wanting to ensure a proper number distribution such as uniform, normal, or Bernoulli, the new standard random library distribution constructs should be used.
- However, the default random number generator should be replaced by a better one like PCG.
Make Coding Better
Many of the new additions can be described (perhaps derisively) as “syntactic sugar”, meaning nothing is fundamentally added that could not be done before – the new way is just spelled differently (usually with less characters). This is a good thing when it makes programmers’ lives easier, but can also be a bad thing if it adds more confusion for subsequent code readers or clutters the programmers’ view of the language. This section outlines the more popular additions in this category, and when to use them.
Automatic Type Deduction
Definition
In some dynamically typed languages like Javascript, variables can be declared and given any type, whether an integer, string, user-defined type, etc. This is convenient for the programmer initially but can become confusing or even buggy due to the lack of type safety and readability on the type of data the code is working with. C++11 retains its static strongly-typed nature, but allows the compiler to insert the variable type in place of the programmer doing it. Note that, as before, once a variable is given a type, it cannot be changed.
These two lines will have the same type of User.
auto hero = User("Geralt");
User hero = User("Geralt");
Automatic type deduction is particularly useful when templated types start getting long and messy.
unordered_map<string, User>::const_iterator userIt = userLookupMap.find("Geralt");
// VS.
auto userIt = userLookupMap.find("Geralt");
Another common pattern you may see in code is in combination with the range-based for loop.
// Confusing - is user a User, std::string, int userid??
for (const auto& user : users) { ... }
While the for-each loop construct can help with comprehension and add simplicity, it’s not recommended to add in auto because that only reduces readability.
Many experts advocate heavy use of auto due to its ability to reduce screen clutter, enforce initialization, make some future refactorings easier, and to reduce instances of a certain class of type-casting bugs. There are also some advanced use cases that would be extremely difficult if not impossible to type without the use of auto, like when templates get involved or lambdas are used.
However, these rare cases and conveniences are not worth the reduced readability for the everyday programmer in my opinion, since all information about the type of the variable is removed and replaced with only the word ‘auto’. One rebuttal to that is modern IDEs can give type highlighting, but that is a poor argument since it requires external tools to solve a problem created by a language construct. The juice is simply rarely worth the squeeze. Using a type alias can be a good compromise.
Warning: make sure to consider variable qualifiers such as const and reference
Advice
Sometimes use auto to allow the compiler to automatically deduce type if (special advanced cases excluded):
- Type clutter is hurting the readability of the code.
- It doesn’t make sense to use a type alias to reduce that type clutter, such as if there’s no meaningful name that can be given to the alias.
- The type of the variable is immediately apparent to the reader: either obvious by the initialization, or visible on the screen within a reasonable distance. For example, in a tight looping structure.
Scoped Enumeration (Enum Class)
Definition
An enum class, or scoped enum, takes care of some annoyances about using traditional C++ enumerations. They have stronger type safety since they aren’t implicitly cast to integers, they can be forward-declared, and their values are not bubbled up into the surrounding scope causing “namespace pollution”. Their numeric values can still be used, but only with an explicit static_cast(). It is also easier, in my opinion, to read code containing FruitType::APPLE instead of FRUIT_TYPE_APPLE, or even worse, just APPLE. The size of the underlying type can also be specified with a colon after the class name. By default, it uses an int type, whereas a typical enum leaves the type up to the compiler. One last note: confusingly, an enum class is not a normal class and therefore can’t participate in inheritance nor contain functions!
enum class FruitType : char {APPLE, ORANGE, PEAR};
int numUsers = FruitType::APPLE; // Doesn't compile – correctly!
Advice
- Scoped enumerations (
enum class)should be used wherever possible due to the increased type safety and lack of namespace pollution. - Where they are declared, the underlying type to use should always be given in order to combat confusion and to decrease the memory footprint where possible.
Range-Based For Loop
Definition
An extremely common looping paradigm is to take some action on every member of a container. Many modern programming languages have foreach or range-based for loop constructs. C++11 brings the latter in, allowing more readable looping code than the traditional for loop, iterator-based, or for_each() function approaches. Not to mention that these traditional methods are susceptible to out-of-range bugs that the range-based loop is not, and can also be less performant in some situations. Range-based for loops are nice, but not always practical if knowledge about the index is needed, or if the container is to be modified. The code below shows four methods of performing an action on each member of a container, including range-based for loop as the final method.
// Off-by-one-bug prone
for (int k=0; k<allUsers.size(); k++) {
doSomething(allUsers[k]);
}
// Blech, too long
for(vector<User>::const_iterator it=allUsers.begin(); it!=allUsers.end(); it++){
doSomething(it);
}
// Too complicated
std::for_each(allUsers.begin(), allUsers.end(), doSomething);
// Nice and clean!
// Also reminds reader of the container elements' type
for (const User& user : allUsers) {
doSomething(user);
}
You may be tempted to use automatic type deduction - auto - but you should resist the urge. It usually only sours a good usage of a range for by hiding the type and making the reader search for the container declaration to see the type of its elements.
// Confusing - is user a User, std::string, integer userid??
for (const auto& user : allUsers) { ... }
Warning: make sure to consider variable qualifiers such as const and reference
- Use const-reference (
const&) for unchanged class objects - Use regular reference (
&) for modification access to the container’s elements - Use value syntax (specify nothing) for primitives
// 1. Read-only class object
for(const User& user: allUsers) {}
// 2. Modifiable class object
for(User& userToEdit: allUsers) {}
// 3. Read-only primitive
for(int userid: userids) {}
Advice
- Sometimes use range-based for loops when iterating over a container if readability is improved
- Unless there is a practical reason why another construct is more appropriate or required
- Container modification
- Index knowledge
- Bidirectional iteration
- Unless there is a practical reason why another construct is more appropriate or required
- Use the appropriate variable qualifiers
- Don’t use
autoinstead of specifying the type of the element
Type aliases
Definition
C++ programmers are likely familiar with the typedef syntax for simplifying a long type name down to a shorter one, or an alias. Two problems exist with that syntax: it does not support templates, and can result in odd phrasing for things like function pointers. These are illustrated in the code snippet below.
// template "typedef" allowed in C++11
template <class T>
using StringMap = std::map<std::string, T>; // Only in C++11
// valid C++98 - confusing
typedef bool (*compare)(int, int);
// valid C++11 - less confusing
using compare = bool (*)(int, int);
Advice
Always use the new using syntax when defining a type alias, instead of typedef.
Delegating Constructors
Definition
Delegating Constructors allows the programmer to call one constructor inside of another. This can be helpful for reducing the amount of boilerplate code duplication in a class, thus decreasing bug potential while increasing readability. In some cases, this can be avoided in an easier way by using braced member initialization.
class User {
User(string name) {…} // name passed in
User() : User("Jane Doe") {} // constructor delegation
};
Advice
Take advantage of delegating constructors when it makes sense and reduces duplication of boilerplate code.
Inherited Constructors
Definition
This feature is similar to delegating constructors, but differs in that you can specify that a class should inherit constructors from its base class. This only works if the derived class has no additional member variables, like the class PowerUser below. Otherwise, those variables will go uninitialized unless member initialization is used. In the example below, however, the second line more clearly states what it is doing, whereas the using syntax in this context is unintuitive.
class PowerUser : public User {
using User::User; // PowerUser inherits User constructors
// VS
PowerUser() : User() {} // call User constructor manually
};
Advice
- If the derived class has no additional member variables and it will make the class definition better or cleaner, consider inheriting all constructors from the base class
- Otherwise, skip this feature and explicitly call base class constructors inside matching derived class constructors
Minor Features
This section contains features that a programmer may want to be aware of in case they come across them, but are minor enough that are not worth more discussion.
std::algorithm Additions
Definition
The standard algorithm collection has a number of additional functions, including [all|any|none]_of, is_sorted(), and min/max taking an arbitrary-sized initializer list. These functions may be useful in some contexts, but are not by themselves important enough to highlight prominently in this text.
Advice
Be aware of additional algorithm module functions available for usage in the standard library.
Forward List
Definition
A new container forward_list is added that is similar to list except it’s singly-linked instead of doubly-linked, meaning it can only be forward-iterated as the name implies. It also does not have a size member, so calculating the size is slow. This object takes up less space and can thus be faster for insertion and forward iteration, at the cost of more limited functionality.
Advice
- Use
listif you need object references to remain valid through any insertions, and don’t know the max size beforehand - Otherwise,
vectoris typically more useful and performant due to spatial locality 17 - Use the more efficient
forward_listoverlistif you don’t need reverse iteration, size, nor arbitrary deletion.
Tuple
Definition
A tuple is an ordered sequence of N values stored compactly together. It’s basically an unnamed struct. Most C++ programmers will be familiar with pair, the C++98-available construct of a tuple where N is 2. As with pair, tuple can be heterogeneous, and there is also a convenience function make_tuple() which deduces the type of the tuple by the values passed in to be stored. Since tuple carries no meaning inside its name as to the practical usage of the container, it should be used conservatively.
Advice
Prefer named classes/structs for better readability, but tuple can be used in the following cases:
- Types are unknown except to the compiler – i.e., template programming.
- There is no logical, meaningful name for the collection.
- The collection is short-lived and narrow in scope, and naming it does not increase readability.
Double Right Angle Brackets
Definition
In C++98, two right angle-brackets in a row would be parsed as the >> (shift or extraction) operator, so could not be used on the closing end of a nested template type, such as the below code.
set<pair<int, int> > pairSet; // C++98 and C++11
set<pair<int, int>> pairSet; // C++11 ONLY
Advice
Just know you can do this now, there are not really any practical cases where this will be an issue. You’ll likely soon forget you even couldn’t write it this way before.
Explicit Conversion
Definition
To attempt to curb improper implicit conversions, C++98 class authors could use the keyword explicit on constructors to disallow implicit conversions to be used on parameters. In C++11 this extends to conversion operators as well. For example if you want a class to be able to be used as a bool in an if condition, you can give it a bool conversion operator.
class User
{
operator bool()
{
return this->isValid();
}
};
// Now User objects can be used like this
if (user)
{
...
}
// ... But also like this??
int someNum = user;
By adding the conversion operator in this way, we get a buggy side effect of User now being implicitly converted to a bool whenever no other option is better, like above where it is converted to int through bool. This bug is caught at compile time with the addition of the explicit modifier.
class User
{
explicit operator bool()
{
return this->isValid();
}
};
// Compile error - cannot convert User to int!
int someNum = user;
Advice
Use the explicit modifier in conversion operators when it makes sense
Noexcept
Definition
Akin to attributes, the noexcept modifier tells the compiler you guarantee a particular function will not throw an exception. This affords it many more optimization opportunities as certain code paths are now impossible. Technically it can also be specified conditionally based on the template type, but I will not discuss that here. If a noexcept function does actually throw an exception, the program terminates immediately.
Advice
The average programmer can file away noexcept and forget about it. Except that manually-defined move constructors must become noexcept if possible. It can be used with extra thought to potentially eke out extra performance if necessary.
Attributes
Definition
Attributes of code (usually of a particular function) can be added using the notation [[attribute]], similar to annotations in Java. Attributes shouldn’t provide different functionality, but rather merely provide hints to the compiler about the intention of the code. Later versions of the C++ standard provide more attributes, but in C++11 the only semi-useful attribute is [[noreturn]]. The optimization opportunities afforded by this attribute are likely to be small and rare, though. Some spurious compiler warnings can be avoided in rare cases using this attribute.
Advice
Do not use attributes in C++11.
Templated Library Development Features
A lot of the more advanced C++ functionality is used primarily in core libraries that make heavy use of templates. As such, the everyday programmer doesn’t often need to consider the issues addressed by the new C++11 template programming features. This section discusses these features that are great for C++ library-developing wizards, but likely not regularly needed by mere mortals.
Feature List
Decltype
The operator decltype() returns the declared type of the name or expression passed as its argument. For example, decltype(42ULL) yields unsigned long long. Previously, the gcc compiler offered a similar but inferior operator typeof which should be replaced by decltype(). This operator is useful in generic programming since you may not know the type returned by a certain expression or function involving templates. Particularly, it’s to be used in cases where a type is needed for a non-variable, such as a return type. For declaring a variable that is about to be initialized, auto is the better choice.
Suffix return type syntax
Consider the simple generic programming function below to add two unknown types together. What should be the return type?? string and char* is a string, double and int is a double, but QueryResult and QueryResult could be a MultiQueryResult!
template <typename Type1, typename Type2>
??? add (Type1 x, Type2 y) {
return x + y;
}
The suffix return type syntax, though it looks a bit awkward and confusing, solves this problem. The return type of this function is, naturally, whatever (x + y) is; i.e., decltype (x + y). Since x and y aren’t declared yet in the normal return type specification location, we can replace that with auto and provide a suffix return type following ->.
template <typename Type1, typename Type2>
auto add (Type1 x, Type2 y) -> decltype (x + y) {
return x + y;
}
Variadic Templates
Variadic arguments, a C-language import to C++, allow a function such as printf() to be called with an arbitrary number of arguments. There are a number of issues with this type of approach because typical type checking is almost entirely removed and the burden of correctness placed on the caller and function implementer. Consider when the format specifier for string, %s, is passed to printf() but the argument given is, say, an int – undefined behavior abounds! Or if the number of format specifiers doesn’t match the number of arguments! Variadic templates in C++11 gives a similar expressive power, while maintaining type safety of the arguments passed in. A simple example below 24 provides an adder function that will work with any number of arguments of compatible type, but importantly, will also throw a compiler error if given incompatible types such as string and int.
template <typename T>
T adder(T v) { // base case
return v;
}
// Variadic template
template <typename T, typename... Args>
T adder(T first, Args... args) { // recursive case
return first + adder(args…); // 'peel off' more arguments
}
Note that while the example does use recursion, it’s recursion that’s evaluated at compile time instead of runtime, making it possibly run faster than its C-style variadic arguments counterpart! Variadic templates enable tuple, make_shared(), and emplace_back(), among others.
Metaprogramming: Type Traits and Static Assertion
Template Metaprogramming (TMP) in C++ has been a burgeoning buzz word in the subfield of generic programming, made easier in C++11. Metaprogramming means writing code that tells the compiler to write more code. It sounds like sorcery (and can end up looking like it too), but the concept is actually fairly simple relative to templates: providing specializations of templates in certain ways to generate new classes/functions at compile time. In practice, it can get very complex; TMP is actually a fully Turing-complete language 25! As an example, the compile-time factorial code can from the constexpr section (3.2.1) can be written using TMP.
template <unsigned int n>
struct factorial {
enum { value = n * factorial<n - 1>::value };
};
template <>
struct factorial<0> {
enum { value = 1 };
};
unsigned int result=factorial<4>::value // 24 – computed at compile time!
In addition to other features discussed in section 5, the C++ standard provides various type_traits that can be used, which obtain characteristics about types in the form of compile-time constants. Thus, allowing functions to be tailored to specific classes without over-specializing (exact implementation too complicated to include here). Some examples include is_integral(), is_assignable(), and is_pointer(). We can also throw a compile-time error if a function or class will not work with the given type, via static_assert. This is a lot better than throwing a runtime exception or having undefined behavior if a template type invariant is not met.
Miscellaneous
Local and unnamed classes can be used as template arguments, previously disallowed. Template specializations can be explicitly declared to suppress multiple instantiations in a translation unit using extern. Additionally, the functional module provides a function class to represent a callable element (function, function pointer, or function object) for use as arguments or member variables, and a bind() function which binds variables to a particular function to make a function object.
Template Programming Advice
- Read additional references on any topics to be used in this section, as generic programming is advanced and full of subtlety
- When the return type of a function is dependent on an expression, use
decltype()in combination with the suffix return type idiom - For use with a variable declaration,
autois more appropriate - Use variadic templates instead of variadic arguments for better type safety.
- Template metaprogramming will make the everyday programmer’s life worse not better, and should only be used by hardcore generic library authors and performance hawks.
Esoteric and Advanced Features
This section contains short descriptions of C++11 miscellany not discussed elsewhere. They may be useful in certain contexts, but are so esoteric or advanced that it’s not worth calling attention to the everyday programmer. Advice is not provided.
Reference Wrapper
std::reference_wrapper emulates a typical reference – i.e., pointer behavior with non-null value semantics – except it can also be copied. For this reason, the wrappers can be stored in containers. The assignment operator assigns a new reference to the wrapper instead of calling the referred-to object’s assignment operator.
Raw String Literals
Heavily motivated by the standard regular expression library arriving with C++11, the raw string literal allows a literal string to be interpreted with backslash characters (‘\’) as just a backslash and not an escape character. To insert one backslash as an escape character for the regular expression, regular string literals require two backslashes – one to escape the other. This can quickly lead to unreadable expressions. The notation for raw string literals is R"(...)", such as R"(\w\\\w)". The corresponding regular string literal would be "\\w\\\\\\w".
User-Defined Literals
Literals could always be specified for some built-in types like char ('a'), float (1.2F vs 1.2 for double), and hexadecimal (0xab), among others. User-defined literals can also be made now, with the operator "". This allows creation of commonly-requested literals such as binary, imaginary numbers, and expression of units (5km vs 5mi, for example).
Unicode Characters
The standard adds supports for Unicode characters with char16_t (UTF-16) and char32_t (UTF-32), and corresponding literals (u"" and U""). Support in standard libraries seems to be somewhat minimal, however, and not recommended.
Inline Namespace
A namespace can be modified as inline which places the contents of the namespace within that namespace’s scope but also outside the namespace in the surrounding scope. This can be used in versioning schemes where other versions can be explicitly called out and used, but some default version is applied if no namespace is specified.
Scoped Allocators
Custom allocators can now contain state. This could be used to perform a special allocation methodology among a pool of resources, for example.
Manual Memory Alignment
If one is manipulating raw memory, extra precision is possible in C++11 with the alignas operator – which specifies a desired memory alignment – and the alignof operator – which returns the type alignment of its argument.
Garbage Collection Definition
An Application Binary Interface (ABI) and rules of operation are provided for how a garbage collector (GC) can be used. Of course, using a library implementation with a GC is optional, but not recommended.
Quick_exit
Calling quick_exit() will immediately terminate the program without calling any destructors, except for code registered with at_quick_exit(). This is opposed to calling exit() which will terminate the program but will call destructors first, or abort() which causes immediate abnormal program termination.
__cplusplus
The macro __cplusplus will be set to a value greater than 199711L, and will almost certainly be set as 201103L.
Acknowledgements
This work relies heavily on materials from and opinions of C++ experts included in references: Bjarne Stroustrup (C++ creator, Standard C++ Foundation Director), Herb Sutter (ISO C++ Committee Chair), and Scott Meyers (C++ guru), as well as all C++ wiki contributors. Also thanks to Chris at null program for editing.
References
C++ logo is from isocpp
-
TIOBE. (2019, November). TIOBE Index. Retrieved from TIOBE: https://www.tiobe.com/tiobe-index ↩
-
Stroustrup, B. (2016). C++11 - the new ISO C++ standard. Retrieved from http://www.stroustrup.com/C++11FAQ.html ↩ ↩2 ↩3
-
Stroustrup, B. (2012). Keynote: C++11 Style. GoingNative. Redmond, WA. Retrieved from MSDN Channel9: https://channel9.msdn.com/Events/GoingNative/GoingNative-2012/Keynote-Bjarne-Stroustrup-Cpp11-Style ↩
-
Meyers, S. (2018). Effective Modern C++. Sebastopol, CA: O’Reilly. ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Standard C++ Foundation. (2019). C++ FAQ. Retrieved from ISO Cpp: https://isocpp.org/faq ↩
-
Sutter, H. (2011). Elements of Modern C++ Style. Retrieved from Sutter’s Mill: https://herbsutter.com/elements-of-modern-c-style/ ↩ ↩2 ↩3
-
Calandra, A. (2019). Modern Cpp Features. Retrieved from Github: https://github.com/AnthonyCalandra/modern-cpp-features ↩
-
Wiki Contributors. (2017). Retrieved from Cpp Reference: https://en.cppreference.com/w/cpp ↩
-
Wiki Contributors. (2019). Retrieved from C Plus Plus Reference: http://www.cplusplus.com/reference/ ↩
-
Lischner, R. (2013). Exploring C++. New York: Apress. ↩
-
Grimm, R. (2016, December). Copy versus Move Semantics: A few Numbers. Retrieved from Modernes C++: https://www.modernescpp.com/index.php/copy-versus-move-semantic-a-few-numbers ↩
-
Isensee, P. (2012). Faster C++: Move Construction and Perfect Forwarding. Game Developers Conference. San Francisco, CA. Retrieved from GDC Vault: https://www.gdcvault.com/play/1015458/Faster-C-Move-Construction-and ↩
-
Stroustrup, B., & Sutter, H. (2019). CPP Core Guidelines. Retrieved from ISO CPP: https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines ↩ ↩2
-
GNU Project. (2019). unique_ptr.h. Retrieved from gcc-mirror: https://github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/include/bits/unique_ptr.h ↩
-
Kieras, D. (2016). Using C++11’s Smart Pointers. Retrieved from EECS 381 - Object Oriented and Advanced Programming: http://umich.edu/~eecs381/handouts/C++11_smart_ptrs.pdf ↩
-
James, D. (2008). Function template hash_combine. Retrieved from Boost C++ Libraries: https://www.boost.org/doc/libs/1_55_0/doc/html/hash/reference.html ↩
-
Sutter, H. (2014). Modern C++: What You Need to Know. Build 2014. San Francisco. Retrieved from MSDN Channel9: https://channel9.msdn.com/Events/Build/2014/2-661 ↩ ↩2
-
Compiler Explorer. https://godbolt.org/z/vXoXJ6 ↩
-
Mertz, A. (2015). Simplify C++. Retrieved from The Rule of Zero revisited: The Rule of All or Nothing: https://arne-mertz.de/2015/02/the-rule-of-zero-revisited-the-rule-of-all-or-nothing/ ↩
-
Meyers, S. (2014). A concern about the Rule of Zero. Retrieved from View from Aristeia: http://scottmeyers.blogspot.com/2014/03/a-concern-about-rule-of-zero.html ↩
-
Kieras, D. (2015). Using C++ Lambdas. Retrieved from EECS 381 - Object Oriented and Advanced Programming: http://umich.edu/~eecs381/handouts/Lambda.pdf ↩
-
Brown, W. E. (2013). Random Number Generation in C++11. ISO Cpp. Retrieved from ISO CPP: https://isocpp.org/files/papers/n3551.pdf ↩
-
O’Neill, M. (2014). PCG: A Family of Simple Fast Space-Efficient Statistically Good Algorithms for Random Number Generation. Retrieved from PCG Random: https://www.pcg-random.org/pdf/toms-oneill-pcg-family-v1.02.pdf ↩
-
Bendersky, E. (2014). Variadic Templates in C++. Retrieved from The Green Place: https://eli.thegreenplace.net/2014/variadic-templates-in-c/ ↩
-
Veldhuizen, T. L. (2003). C++ Templates are Turing Complete. Indiana University Computer Science. doi: 10.1.1.14.3670 ↩